
📺 Calculateur taille écran idéal
Distance recommandée selon la taille et résolution. Pour 4K, on peut s'asseoir 2× plus près qu'en HD.
Questions courantes
Qu’est-ce que le langage SQL ?
Le langage SQL (Structured Query Language) est un langage de requête utilisé pour gérer et manipuler des données dans des bases de données relationnelles.
Pourquoi apprendre le langage SQL ?
Apprendre le langage SQL est essentiel pour quiconque souhaite travailler avec des données, car il permet de récupérer, de manipuler et de analyser des données de manière efficace.
Qu’est-ce que MySQL ?
MySQL est un système de gestion de bases de données relationnelles qui utilise le langage SQL pour stocker et gérer des données.
Je suis chercheur en intelligence artificielle, donc l’une des principales choses dont je m’occupe, ce sont les données. Beaucoupde données.
Les bases de données relationnelles et le langage SQL
Les bases de données relationnelles sont des systèmes de gestion de données qui stockent des informations dans des tables liées entre elles. Le langage SQL est utilisé pour interroger et manipuler ces données.
Pour en savoir plus sur les bases de données relationnelles, vous pouvez consulter notre article Apprendre SQL – Cours gratuits sur les bases de données relationnelles pour les débutants.
Dans cet article, nous allons vous présenter un aide-mémoire des commandes SQL pour vous aider à apprendre le langage SQL en 10 minutes.
Avec plus de 2,5 exaoctets de données générées chaque jour, il n’est pas surprenant que ces données doivent être stockées quelque part où nous pouvons y accéder quand nous en avons besoin.
Cet article vous guidera à travers un aide-mémoire qui vous permettra d’être rapidement opérationnel avec SQL.
## Qu’est-ce que le langage SQL ?SQL est l’abréviation de Structured Query Language (langage de requête structuré). Il s’agit d’un langage destiné aux systèmes de gestion de bases de données relationnelles. SQL est utilisé aujourd’hui pour stocker, récupérer et manipuler des données dans des bases de données relationnelles.
Voici à quoi ressemble une base de données relationnelle de base :
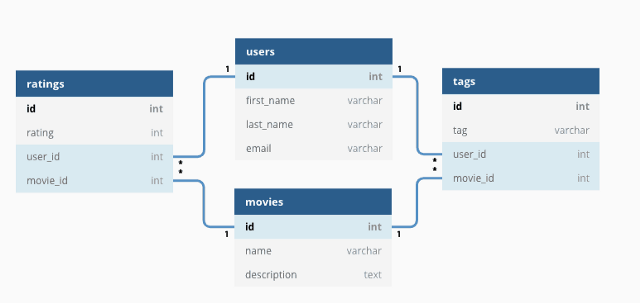
{kind=link}
Voici à quoi ressemble un exemple de requête :
SELECT * FROM customers ;
En utilisant cette instruction SELECT, la requête sélectionne toutes lesdonnées de toutes les colonnes de la table du client et renvoie les données comme suit :
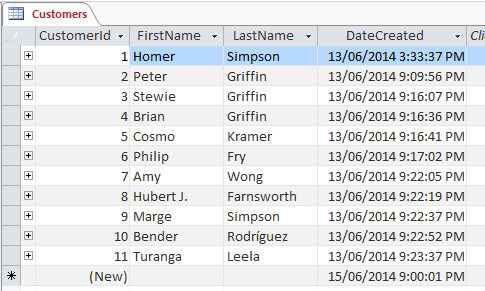
SELECT FirstName, LastName FROM customers ;
L’ajout d’une clause WHERE vous permet de filtrer ce qui est renvoyé :
SELECT * FROM customers WHERE age >= 30 ORDER BY age ASC ;
Cette requête renvoie toutes les données de la table des produits dont la valeur d’âge est supérieure à 30.
L’utilisation du mot clé ORDER BY signifie simplement que les résultats seront classés en fonction de la colonne d’âge, de la valeur la plus faible à la plus élevée
L’instruction INSERT INTO permet d’ajouter de nouvelles données à une table. Voici un exemple de base pour ajouter un nouvel utilisateur à la table des clients :
INSERT INTO clients(FirstName, LastName, adresse, email) VALUES ('Jason', 'Dsouza', 'McLaren Vale, South Australia', 'test@fakeGmail.com') ;
Bien entendu, ces exemples ne montrent qu’une infime partie de ce que le langage SQL peut faire. Nous en apprendrons davantage dans ce guide.

Pourquoi apprendre le langage SQL ?
Nous vivons à l’ère du Big Data, où les données sont utilisées de manière intensive pour trouver des idées et informer la stratégie, le marketing, la publicité et une pléthore d’autres opérations.
Les grandes entreprises comme Google, Amazon, AirBnb utilisent de grandes bases de données relationnelles pour améliorer l’expérience client. Comprendre le langage SQL est une excellente compétence à posséder, non seulement pour les scientifiques et les analystes de données, mais pour tout le monde.
Comment pensez-vous que vous ayez soudainement reçu une publicité Youtube sur des chaussures alors qu’il y a quelques minutes à peine, vous étiez en train de chercher vos chaussures préférées sur Google ? C’est le SQL (ou une forme de SQL) à l’œuvre !

SQL vs MySQL
Avant de poursuivre, je tiens à clarifier un sujet qui prête souvent à confusion : la différence entre SQL et MySQL. Il s’avère qu’il ne s ‘agit pasde la même chose !
SQL est un langage, tandis que MySQL est un système permettant de mettre en œuvre SQL.
SQL décrit la syntaxe qui vous permet d’écrire des requêtes qui gèrent les bases de données relationnelles.
MySQL est un système de base de données qui fonctionne sur un serveur. Il vous permet d’écrire des requêtes en utilisant la syntaxe SQL pour gérer les bases de données MySQL.
En plus de MySQL, il existe d’autres systèmes qui mettent en œuvre SQL. Parmi les plus populaires, citons :
- SQLite
- Base de données Oracle
- PostgreSQL
- Microsoft SQL Server
Comment installer MySQL
Dans la plupart des cas, MySQL est le choix préféré pour un système de gestion de base de données. De nombreux systèmes de gestion de contenu populaires (comme WordPress) utilisent MySQL par défaut, et l’utilisation de MySQL pour gérer ces applications peut être une bonne idée.
Afin d’utiliser MySQL, vous devez l’installer sur votre système :
Installer MySQL sous Windows
La méthode recommandée pour installer MySQL sur Windows est d’utiliser le programme d’installation MSI du site Web de MySQL.
N’oubliez pas de me suivre sur Twitter pour obtenir des mises à jour sur les futurs articles. Bon apprentissage !
Sous macOS, l’installation de MySQL implique également le téléchargement d’un programme d’installation.
Dans cet exemple, les données transmises à la colonne id doivent être un int (nombre entier), tandis que la colonne FirstName a un type de données VARCHAR avec un maximum de 255 caractères.
Une fois MySQL installé sur votre système, je vous recommande d’utiliser une sorte d’application de gestion SQL pour faciliter la gestion de vos bases de données.
Il existe de nombreuses applications qui remplissent en grande partie la même fonction, c’est donc à vous de choisir celle que vous voulez utiliser :
Lorsque vous êtes prêt à écrire vos propres requêtes SQL, envisagez d’importer des données factices plutôt que de créer votre propre base de données.
Voici quelques bases de données factices que vous pouvez télécharger gratuitement.
Cheatsheet SQL – La cerise sur le gâteau
Mots clés SQL
Vous trouverez ici une collection de mots-clés utilisés dans les instructions SQL, une description et, le cas échéant, un exemple. Certains des mots-clés les plus avancés ont leur propre section dédiée.
Lorsque MySQL est mentionné à côté d’un exemple, cela signifie que cet exemple s’applique uniquement aux bases de données MySQL (par opposition à tout autre système de base de données).
`ADD — Ajoute une nouvelle colonne à une table existante
ADD CONSTRAINT — Crée une nouvelle contrainte sur une table existante, qui est utilisée pour spécifier des règles pour toutes les données de la table.
ALTER TABLE — Ajoute, supprime ou modifie des colonnes dans une table. Il peut également être utilisé pour ajouter et supprimer des contraintes dans une table, comme indiqué ci-dessus.
ALTER COLUMN — Modifie le type de données d’une colonne d’une table.
ALL — Retourne vrai si toutes les valeurs de la sous-requête répondent à la condition passée.
AND — Utilisé pour joindre des conditions distinctes dans une clause WHERE.
ANY — Renvoie un message vrai si l’une des valeurs de la sous-requête répond à la condition donnée.
AS — Renomme une table ou une colonne avec une valeur alias qui n’existe que pour la durée de la requête.
ASC — Utilisé avec ORDER BY pour retourner les données dans l’ordre croissant.
BETWEEN — Sélectionne les valeurs comprises dans la plage donnée.
CASE — Modifie la sortie de la requête en fonction des conditions.
CHECK — Ajoute une contrainte qui limite la valeur qui peut être ajoutée à une colonne.
CREATE DATABASE — Crée une nouvelle base de données.
CREATE TABLE — Crée une nouvelle table
DEFAULT — Définit une valeur par défaut pour une colonne
DELETE — Supprime les données d’une table.
DESC — Utilisé avec ORDER BY pour retourner les données dans l’ordre décroissant.
DROP COLUMN — Supprime une colonne d’une table.
DROP DATABASE — Supprime l’ensemble de la base de données.
DROP DEAFULT — Supprime une valeur par défaut pour une colonne.
DROP TABLE — Supprime une table d’une base de données.
EXISTS — Vérifie l’existence d’un enregistrement dans la sous-requête, et renvoie true si un ou plusieurs enregistrements sont retournés.
FROM — Spécifie la table dans laquelle les données doivent être sélectionnées ou supprimées.
IN — Utilisé avec une clause WHERE comme raccourci pour des conditions OR multiples.
INSERT INTO — Ajoute de nouvelles lignes à une table.
IS NULL — Teste les valeurs vides (NULL).
IS NOT NULL — L’inverse de NULL. Teste les valeurs qui ne sont pas vides / NULL.
LIKE — Retourne un résultat vrai si la valeur de l’opérande correspond à un modèle.
NOT — Retourne vrai si un enregistrement ne remplit pas la condition.
OR — Utilisé avec WHERE pour inclure des données lorsque l’une des deux conditions est vraie.
ORDER BY — Utilisé pour trier les données du résultat en ordre croissant (par défaut) ou décroissant grâce à l’utilisation des mots-clés ASC ou DESC.
ROWNUM — Renvoie les résultats pour lesquels le numéro de ligne répond à la condition passée.
SELECT — Utilisé pour sélectionner des données dans une base de données, qui sont ensuite retournées dans un ensemble de résultats.
SELECT DISTINCT — Identique à SELECT, sauf que les valeurs dupliquées sont exclues.
SELECT INTO — Copie les données d’une table et les insère dans une autre.
SELECT TOP — Permet de retourner un nombre défini d’enregistrements à partir d’une table.
SET — Utilisé avec UPDATE pour mettre à jour les données existantes dans une table.
SOME — Identique à ANY.
TOP — Utilisé avec SELECT pour retourner un nombre déterminé d’enregistrements d’une table.
TRUNCATE TABLE — Semblable à DROP, mais au lieu de supprimer la table et ses données, cette fonction ne supprime que les données.
UNION — Combine les résultats de 2 ou plusieurs instructions SELECT et ne renvoie que des valeurs distinctes.
UNION ALL — Identique à UNION, mais inclut les valeurs en double.
UNIQUE — Cette contrainte garantit que toutes les valeurs d’une colonne sont uniques.
UPDATE — Met à jour les données existantes dans une table.
VALUES — Utilisé avec le mot-clé INSERT INTO pour ajouter de nouvelles valeurs à une table.
WHERE — Filtre les résultats pour n’inclure que les données qui répondent à la condition donnée.` Les commentaires vous permettent d’expliquer des sections de vos instructions SQL, sans les exécuter directement.
En SQL, il existe deux types de commentaires : les commentaires d’une seule ligne et les commentaires multilignes.
Les commentaires sur une seule ligne commencent par ‘- -‘. Tout texte après ces 2 caractères jusqu’à la fin de la ligne sera ignoré.
`— Cette partie est ignorée
SELECT * FROM clients ;` Les commentaires multilignes commencent par /* et se terminent par */. Ils s’étendent sur plusieurs lignes jusqu’à ce que les caractères de fermeture aient été trouvés.
`/*
Il s’agit d’un commentaire multiligne. Il peut s’étendre sur plusieurs lignes.
*/
SELECT * FROM clients ;
/*
Ceci est un autre commentaire Vous pouvez même mettre du code à l’intérieur d’un commentaire pour empêcher son exécution
SELECT * FROM icecreams ;
*/`
Types de données dans MySQL
Lorsque vous créez une nouvelle table ou que vous modifiez une table existante, vous devez spécifier le type de données que chaque colonne accepte.
`CREATE TABLE customers( id int, FirstName varchar(255) ) ;` #### 1. Types de données de type String`CHAR(size) — Chaîne de longueur fixe qui peut contenir des lettres, des chiffres et des caractères spéciaux. Le paramètre size définit la longueur maximale de la chaîne, de 0 à 255, avec une valeur par défaut de 1.
VARCHAR(size) — Chaîne de longueur variable similaire à CHAR(), mais avec une longueur maximale comprise entre 0 et 65535.
BINARY(size) — Similaire à CHAR() mais stocke des chaînes d’octets binaires.
VARBINARY(size) — Similaire à VARCHAR() mais pour les chaînes d’octets binaires.
TINYBLOB — Contient des BLOBs (Binary Large Objects) d’une longueur maximale de 255 octets.
TINYTEXT — Contient une chaîne de caractères d’une longueur maximale de 255 caractères. Utilisez VARCHAR() à la place, car il est récupéré beaucoup plus rapidement.
TEXT(size) — Contient une chaîne de caractères d’une longueur maximale de 65535 octets. Là encore, il est préférable d’utiliser VARCHAR().
BLOB(size) — Contient des Binary Large Objects (BLOBs) d’une longueur maximale de 65535 octets.
MEDIUMTEXT — Contient une chaîne de caractères d’une longueur maximale de 16 777 215 caractères.
MEDIUMBLOB — Contient des Binary Large Objects (BLOBs) d’une longueur maximale de 16 777 215 octets.
LONGTEXT — Contient une chaîne de caractères d’une longueur maximale de 4 294 967 295 caractères.
LONGBLOB — Contient des grands objets binaires (BLOB) d’une longueur maximale de 4 294 967 295 octets.
ENUM(a, b, c, etc…) — Un objet chaîne qui n’a qu’une seule valeur, choisie dans une liste de valeurs que vous définissez, jusqu’à un maximum de 65535 valeurs. Si une valeur qui n’est pas dans cette liste est ajoutée, elle est remplacée par une valeur vide.
SET(a, b, c, etc…) — Un objet chaîne qui peut avoir 0 ou plusieurs valeurs, choisies dans une liste de valeurs que vous définissez, jusqu’à un maximum de 64 valeurs.`
2. Types de données numériques
`BIT(size) — Un type de valeur binaire avec une valeur par défaut de 1. Le nombre de bits autorisé dans une valeur est défini par le paramètre size, qui peut contenir des valeurs de 1 à 64.
TINYINT(size) — Un très petit entier avec une plage signée de -128 à 127, et une plage non signée de 0 à 255. Ici, le paramètre size spécifie la largeur d’affichage maximale autorisée, qui est de 255.
BOOL — Essentiellement un moyen rapide de définir la colonne en TINYINT avec une taille de 1. 0 est considéré comme faux, tandis que 1 est considéré comme vrai.
BOOLEAN — Même chose que BOOL.
SMALLINT(size) — Un petit entier avec une plage signée de -32768 à 32767, et une plage non signée de 0 à 65535. Ici, le paramètre size spécifie la largeur d’affichage maximale autorisée, qui est de 255.
MEDIUMINT(size) — Un nombre entier moyen avec une plage signée de -8388608 à 8388607, et une plage non signée de 0 à 16777215. Ici, le paramètre size spécifie la largeur d’affichage maximale autorisée, qui est de 255.
INT(size) — Un nombre entier moyen avec une plage signée de -2147483648 à 2147483647, et une plage non signée de 0 à 4294967295. Ici, le paramètre size spécifie la largeur d’affichage maximale autorisée, qui est de 255.
INTEGER(size) — Identique à INT.
BIGINT(size) — Un nombre entier moyen avec une plage signée de -9223372036854775808 à 9223372036854775807, et une plage non signée de 0 à 18446744073709551615. Ici, le paramètre size spécifie la largeur d’affichage maximale autorisée, qui est de 255.
FLOAT(p) — Une valeur numérique à virgule flottante. Si le paramètre precision (p) est compris entre 0 et 24, alors le type de données est défini comme FLOAT(), tandis que s’il est compris entre 25 et 53, le type de données est défini comme DOUBLE(). Ce comportement a pour but de rendre le stockage des valeurs plus efficace.
DOUBLE(size, d) — Une valeur numérique à virgule flottante où le nombre total de chiffres est défini par le paramètre size, et le nombre de chiffres après la virgule est défini par le paramètre d.
DECIMAL(size, d) — Un nombre exact à virgule fixe où le nombre total de chiffres est fixé par les paramètres size, et le nombre total de chiffres après la virgule est fixé par le paramètre d.
DEC(size, d) — Identique à DECIMAL.`
3. Types de données Date/Heure
`DATE — Une date simple au format AAAA-MM-JJ, avec une plage prise en charge allant de ‘1000-01-01’ à ‘9999-12-31’.
DATETIME(fsp) — Une date au format YYYY-MM-DD hh:mm:ss, avec une plage de valeurs comprise entre ‘1000-01-01 00:00:00’ et ‘9999-12-31 23:59:59’. En ajoutant DEFAULT et ON UPDATE à la définition de la colonne, celle-ci se règle automatiquement sur la date/heure actuelle.
TIMESTAMP(fsp) — Un horodatage Unix, qui est une valeur relative au nombre de secondes depuis l’époque Unix (‘1970-01-01 00:00:00’ UTC). Cette valeur est comprise entre ‘1970-01-01 00:00:01’ UTC et ‘2038-01-09 03:14:07’ UTC. En ajoutant DEFAULT CURRENT_TIMESTAMP et ON UPDATE CURRENT TIMESTAMP à la définition de la colonne, celle-ci est automatiquement définie sur la date/heure actuelle.
TIME(fsp) — Une heure au format hh:mm:ss, avec une plage prise en charge allant de ‘-838:59:59’ à ‘838:59:59’.
YEAR — Une année, avec une fourchette comprise entre ‘1901’ et ‘2155’.`
Opérateurs SQL
1. Opérateurs arithmétiques en SQL
`+ — Ajouter — Soustraire
- — Multiplier / — Divise % — Modulus`
2. Opérateurs binaires en SQL
& -- AND au sens du bit | -- OU par bit ^-- XOR par bit
3. Opérateurs de comparaison en SQL
`= — Egal à
— Supérieur à < — Inférieur à = — Supérieur ou égal à <= — Inférieur ou égal à <> — Non égal à`
4. Opérateurs composés en SQL
+= -- Additionne des égaux -= -- Soustrait des égaux *= -- Multiplier des égaux /= -- Divise des égaux %= -- Modulo égal &= -- Égaux AND par bit ^-= -- Égaux exclusifs par bit |*= -- Égaux OU par bit
Fonctions SQL
1. Fonctions de chaîne en SQL
`ASCII — Retourne la valeur ASCII équivalente pour un caractère spécifique.
CHAR_LENGTH — Retourne la longueur de caractère d’une chaîne.
CHARACTER_LENGTH — Identique à CHAR_LENGTH.
CONCAT — Ajoute des expressions ensemble, avec un minimum de 2.
CONCAT_WS — Ajoute des expressions ensemble, mais avec un séparateur entre chaque valeur.
FIELD — Retourne une valeur d’index relative à la position d’une valeur dans une liste de valeurs.
FIND IN SET — Retourne la position d’une chaîne de caractères dans une liste de chaînes de caractères.
FORMAT — Lorsqu’on lui passe un nombre, retourne ce nombre formaté pour inclure des virgules (par exemple 3,400,000).
INSERT — Vous permet d’insérer une chaîne de caractères dans une autre à un certain point, pour un certain nombre de caractères.
INSTR — Retourne la position de la première fois qu’une chaîne apparaît dans une autre.
LCASE — Convertit une chaîne en minuscule.
LEFT — En commençant par la gauche, extrait le nombre donné de caractères d’une chaîne et les retourne sous la forme d’une autre chaîne
LENGTH — Retourne la longueur d’une chaîne, mais en octets.
LOCATE — Retourne la première occurrence d’une chaîne dans une autre,
LOWER — Identique à LCASE.
LPAD — Remplace une chaîne par une autre, à une longueur spécifique.
LTRIM — Supprime les espaces en tête de la chaîne donnée
MID — Extrait une chaîne d’une autre, à partir de n’importe quelle position
POSITION — Retourne la position de la première fois qu’une sous-chaîne apparaît dans une autre.
REPEAT — Permet de répéter une chaîne de caractères
REPLACE — Vous permet de remplacer toutes les instances d’une sous-chaîne dans une chaîne, par une nouvelle sous-chaîne.
REVERSE — Inverse la chaîne de caractères.
RIGHT — En commençant par la droite, extrait le nombre donné de caractères d’une chaîne et les retourne sous la forme d’un autre.
RPAD — Remplace une chaîne de caractères par une autre, à une longueur spécifique.
RTRIM — Supprime les espaces de fin de chaîne d’une chaîne donnée
SPACE — Retourne une chaîne pleine d’espaces, égale à la quantité que vous lui avez passée
STRCMP — Compare 2 chaînes de caractères pour trouver des différences
SUBSTR — Extrait une sous-chaîne d’une autre, à partir de n’importe quelle position
SUBSTRING — Identique à SUBSTR
SUBSTRING_INDEX — Retourne une sous-chaîne d’une chaîne avant que la sous-chaîne passée ne soit trouvée le nombre de fois égal au nombre passé.
TRIM — Supprime les espaces de début et de fin de la chaîne donnée. Comme si vous exécutiez LTRIM et RTRIM ensemble.
UCASE — Convertit une chaîne en majuscules.
UPPER — Identique à UCASE`
2. Fonctions numériques en SQL
`ABS — Retourne la valeur absolue d’un nombre donné.
ACOS — Retourne l’arc cosinus du nombre donné
ASIN — Retourne l’arc sinus du nombre donné
ATAN — Retourne l’arc tangent d’un ou deux nombres donnés.
ATAN2 — Retourne l’arc tangent de 2 nombres donnés.
AVG — Retourne la valeur moyenne d’une expression donnée
CEIL — Retourne le nombre entier (entier) le plus proche vers le haut à partir d’un nombre décimal donné.
CEILING — Identique à CEIL
COS — Retourne le cosinus d’un nombre donné
COT — Retourne la cotangente d’un nombre donné.
COUNT — Retourne le nombre d’enregistrements retournés par une requête SELECT.
DEGREES — Convertit une valeur en radians en degrés.
DIV — Permet de diviser des entiers.
EXP — Retourne e à la puissance du nombre donné
FLOOR — Retourne le nombre entier (entier) le plus proche vers le bas à partir d’un nombre décimal donné.
GREATEST — Retourne la valeur la plus élevée dans une liste d’arguments
LEAST — Retourne la plus petite valeur dans une liste d’arguments.
LN — Retourne le logarithme naturel d’un nombre donné.
LOG — Retourne le logarithme naturel d’un nombre donné, ou le logarithme d’un nombre donné à la base donnée.
LOG10 — Fait la même chose que LOG, mais en base 10.
LOG2 — Fait la même chose que LOG, mais en base 2.
MAX — Retourne la valeur la plus élevée d’un ensemble de valeurs.
MIN — Retourne la valeur la plus basse d’un ensemble de valeurs.
MOD — Retourne le reste d’un nombre donné divisé par un autre nombre donné.
PI — Retourne le PI.
POW — Retourne la valeur du nombre donné élevé à la puissance de l’autre nombre donné.
POWER — Identique à POW.
RADIANS — Convertit une valeur en degrés en radians.
RAND — Retourne un nombre aléatoire
ROUND — Arrondit un nombre donné au nombre de décimales donné
SIGN — Retourne le signe d’un nombre donné
SIN — Retourne le sinus du nombre donné
SQRT — Retourne la racine carrée d’un nombre donné
SUM — Retourne la valeur d’un ensemble de valeurs combinées.
TAN — Retourne la tangente d’un nombre donné
TRUNCATE — Retourne un nombre tronqué au nombre donné de décimales.`
3. Fonctions de date en SQL
`ADDDATE — Ajoute un intervalle de date (ex : 10 DAY) à une date (ex : 20/01/20) et retourne le résultat (ex : 20/01/30).
ADDTIME — Ajoute un intervalle de temps (ex : 02:00) à une heure ou une date (05:00) et retourne le résultat (07:00).
CURDATE — Obtient la date courante.
CURRENT_DATE — Identique à CURDATE.
CURRENT_TIME — Obtient l’heure actuelle.
CURRENT_TIMESTAMP — Récupère la date et l’heure courante.
CURTIME — Identique à CURRENT_TIME.
DATE — Extrait la date d’une expression date-heure
DATEDIFF — Retourne le nombre de jours entre 2 dates données.
DATE_ADD — Identique à ADDDATE.
DATE_FORMAT — Formate la date selon le modèle donné.
DATE_SUB — Soustrait un intervalle de date (ex : 10 DAY) à une date (ex : 20/01/20) et retourne le résultat (ex : 20/01/10).
DAY — Retourne le jour pour la date donnée.
DAYNAME — Retourne le nom du jour de la semaine pour la date donnée.
DAYOFWEEK — Retourne l’index du jour de la semaine pour la date donnée.
DAYOFYEAR — Retourne le jour de l’année pour la date donnée.
EXTRACT — Extrait de la date la partie donnée (ex : MONTH pour 20/01/20 = 01).
FROM DAYS — Retourne la date à partir d’une valeur numérique donnée.
HOUR — Retourne l’heure à partir de la date donnée.
LAST DAY — Retourne le dernier jour du mois pour la date donnée.
LOCALTIME — Retourne la date et l’heure locale actuelle.
LOCALTIMESTAMP — Identique à LOCALTIME.
MAKEDATE — Crée une date et la renvoie, en se basant sur l’année et le nombre de jours donnés.
MAKETIME — Crée une heure et la renvoie, en se basant sur les valeurs heure, minute et seconde données.
MICROSECOND — Retourne la microseconde d’une heure ou d’une date donnée.
MINUTE — Retourne la minute d’une heure ou d’une date donnée.
MONTH — Retourne le mois d’une date donnée.
MONTHNAME — Retourne le nom du mois de la date donnée.
NOW — Identique à LOCALTIME
PERIOD_ADD — Ajoute le nombre de mois donné à la période donnée.
PERIOD_DIFF — Retourne la différence entre 2 périodes données.
QUARTER — Retourne le trimestre de l’année pour la date donnée.
SECOND — Retourne la seconde d’une heure ou d’une date donnée.
SEC_TO_TIME — Retourne une heure basée sur les secondes données.
STR_TO_DATE — Crée une date et la retourne en fonction de la chaîne et du format donnés
SUBDATE — Identique à DATE_SUB.
SUBTIME — Soustrait un intervalle de temps (ex : 02:00) à une heure ou une date (05:00) et retourne le résultat (03:00).
SYSDATE — Identique à LOCALTIME.
TIME — Retourne l’heure à partir d’une heure ou d’une date donnée.
TIME_FORMAT — Retourne l’heure donnée dans le format donné.
TIME_TO_SEC — Convertit et retourne un temps en secondes.
TIMEDIFF — Retourne la différence entre 2 expressions de temps/date données.
TIMESTAMP — Retourne la valeur temporelle d’une date ou d’une heure donnée
TO_DAYS — Retourne le nombre total de jours qui se sont écoulés entre ‘00-00-0000’ et la date donnée.
WEEK — Retourne le numéro de semaine pour la date donnée.
WEEKDAY — Retourne le numéro du jour de la semaine pour la date donnée.
WEEKOFYEAR — Retourne le numéro de la semaine pour la date donnée.
YEAR — Retourne l’année de la date donnée.
YEARWEEK — Retourne l’année et le numéro de semaine pour la date donnée.`
4. Fonctions diverses en SQL
`BIN — Retourne le nombre donné en binaire.
BINARY — Retourne la valeur donnée sous la forme d’une chaîne binaire.
CAST — Convertit un type en un autre.
COALESCE — A partir d’une liste de valeurs, retourne la première valeur non nulle.
CONNECTION_ID — Pour la connexion courante, retourne l’ID de connexion unique.
CONV — Convertit un nombre donné d’un système de base numérique en un autre.
CONVERT — Convertit la valeur donnée dans le type de données ou le jeu de caractères donné.
CURRENT_USER — Retourne l’utilisateur et le nom d’hôte qui ont été utilisés pour s’authentifier auprès du serveur.
DATABASE — Retourne le nom de la base de données courante.
GROUP BY — Utilisé avec les fonctions d’agrégation (COUNT, MAX, MIN, SUM, AVG) pour regrouper les résultats.
HAVING — Utilisé à la place de WHERE avec les fonctions agrégées.
IF — Si la condition est vraie, elle renvoie une valeur, sinon elle renvoie une autre valeur.
IFNULL — Si l’expression donnée est égale à null, elle renvoie la valeur donnée.
ISNULL — Si l’expression est nulle, il retourne 1, sinon il retourne 0.
LAST_INSERT_ID — Pour la dernière ligne qui a été ajoutée ou mise à jour dans une table, renvoie l’ID d’auto-incrémentation.
NULLIF — Compare les 2 expressions données. Si elles sont égales, NULL est retourné, sinon la première expression est retournée.
SESSION_USER — Retourne l’utilisateur actuel et les noms d’hôtes.
SYSTEM_USER — Identique à SESSION_USER.
USER — Identique à SESSION_USER.
VERSION — Retourne la version actuelle du MySQL qui alimente la base de données.`
Caractères génériques en SQL
En SQL, les caractères génériques sont des caractères spéciaux utilisés avec les mots-clés LIKE et NOT LIKE. Cela nous permet de rechercher des données avec des modèles sophistiqués de manière assez efficace.
`% — Correspond à zéro ou plusieurs caractères. — Exemple : Trouver tous les clients dont le nom de famille se termine par ‘ory’. SELECT * FROM clients WHERE surname LIKE ‘%ory’ ;
_ — Correspond à un caractère unique quelconque. — Exemple : Trouver tous les clients vivant dans des villes dont le nom commence par trois caractères, suivis de “vale”. SELECT * FROM clients WHERE city LIKE ’_ _ _ _vale’ ;
[charlist] — Correspond à tout caractère unique de la liste. — Exemple : Trouver tous les clients dont le prénom commence par J, K ou T. SELECT * FROM clients WHERE first_name LIKE ‘[jkt]%’ ;`
Clés SQL
Dans les bases de données relationnelles, il existe un concept de clés primaireset étrangères. Dans les tables SQL, elles sont incluses en tant que contraintes, une table pouvant avoir une clé primaire, une clé étrangère ou les deux.
1. Clés primaires en SQL
Une clé primaire permet d’identifier de façon unique chaque enregistrement d’une table. Vous ne pouvez avoir qu’une seule clé primaire par table, et vous pouvez affecter cette contrainte à n’importe quelle colonne ou combinaison de colonnes. Toutefois, cela signifie que chaque valeur de cette ou ces colonnes doit être unique.
En général, dans une table, la colonne ID est une clé primaire, et elle est généralement associée au mot-clé AUTO_INCREMENT. Cela signifie que la valeur augmente automatiquement au fur et à mesure que de nouveaux enregistrements sont créés.
Exemple (MySQL)
Créez une nouvelle table et définissez la clé primaire sur la colonne ID.
CREATE TABLE customers ( id int NOT NULL AUTO_INCREMENT, FirstName varchar(255), Last Name varchar(255) NOT NULL, adresse varchar(255), email varchar(255), PRIMARY KEY (id) ) ;
2. Clés étrangères en SQL
Vous pouvez appliquer une clé étrangère à une ou plusieurs colonnes. Vous l’utilisez pour relier deuxtables dans une base de données relationnelle.
La table contenant la clé étrangère est appelée clé enfant,
La table contenant la clé référencée (ou candidate) est appelée la table parent.
Cela signifie essentiellement que les données de la colonne sont partagées entre 2 tables, car une clé étrangère empêche également l’insertion de données invalides qui ne sont pas également présentes dans la table parente.
Exemple (MySQL)
Créez une nouvelle table et transformez toutes les colonnes qui font référence à des ID dans d’autres tables en clés étrangères.
CREATE TABLE orders ( id int NOT NULL, user_id int, product_id int, PRIMARY KEY (id), FOREIGN KEY (user_id) REFERENCES users(id), FOREIGN KEY (product_id) REFERENCES products(id) ) ;
Les index en SQL
Les index sont des attributs qui peuvent être assignés aux colonnes qui font l’objet de recherches fréquentes afin de rendre la récupération des données plus rapide et plus efficace.
CREATE INDEX -- Crée un index nommé 'idx_test' sur les colonnes first_name et surname de la table users. Dans ce cas, les valeurs dupliquées sont autorisées. CREATE INDEX idx_test ON users (first_name, surname) ; CREATE UNIQUE INDEX -- La même chose que ci-dessus, mais pas de valeurs dupliquées. CREER UNIQUE INDEX idx_test ON users (first_name, surname) ; DROP INDEX -- Supprime un index. ALTER TABLE users DROP INDEX idx_test ;
Joints en SQL
En SQL, une clause JOIN est utilisée pour renvoyer un résultat qui combine les données de plusieurs tables, sur la base d’une colonne commune qui figure dans les deux tables.
Il existe un certain nombre de jointures différentes que vous pouvez utiliser :
- **Jointure interne (par défaut) :**Renvoie tous les enregistrements qui ont des valeurs correspondantes dans les deux tables.
- Jointure à gauche : Renvoie tous les enregistrements de la première table, ainsi que les enregistrements correspondants de la deuxième table.
- Jointure à droite : Renvoie tous les enregistrements de la deuxième table, ainsi que tous les enregistrements correspondants de la première.
- Jointure complète : Renvoie tous les enregistrements des deux tables lorsqu’il y a une correspondance.
Une façon courante de visualiser le fonctionnement des jointures est la suivante :

Une vue est essentiellement un ensemble de résultats SQL qui est stocké dans la base de données sous une étiquette, de sorte que vous pouvez y revenir plus tard sans avoir à réexécuter la requête.
Elles sont particulièrement utiles lorsque vous avez une requête SQL coûteuse dont vous pouvez avoir besoin un certain nombre de fois. Ainsi, au lieu de l’exécuter plusieurs fois pour générer le même ensemble de résultats, vous pouvez le faire une seule fois et l’enregistrer en tant que vue.
Comment créer des vues en SQL
Pour créer une vue, vous pouvez procéder comme suit :
CREATE VIEW priority_users AS SELECT * FROM utilisateurs WHERE country = 'United Kingdom' ;
Ensuite, à l’avenir, si vous avez besoin d’accéder à l’ensemble de résultats stockés, vous pouvez le faire comme ceci :
SELECT * FROM [priority_users] ;
Comment remplacer des vues en SQL
Avec la commande CREATE OR REPLACE, vous pouvez mettre à jour une vue comme ceci :
CREATE OR REPLACE VIEW [priority_users] AS SELECT * FROM users WHERE country = 'United Kingdom' OR country='USA' ;
Comment supprimer des vues en SQL
Pour supprimer une vue, il suffit d’utiliser la commande DROP VIEW.
DROP VIEW utilisateurs_prioritaires ;
Conclusion
La majorité des sites Web et des applications utilisent des bases de données relationnelles d’une manière ou d’une autre. C’est pourquoi il est extrêmement utile de connaître le langage SQL, car il permet de créer des systèmes plus complexes et fonctionnels.
FAQ
Comment installer MySQL ?
MySQL peut être installé sur différents systèmes d’exploitation, notamment Windows et macOS. Vous pouvez télécharger le logiciel sur le site officiel de MySQL.
Comment utiliser MySQL ?
Une fois MySQL installé, vous pouvez utiliser le langage SQL pour créer des bases de données, insérer des données, les récupérer et les manipuler.
Qu’est-ce qu’une requête SQL ?
Une requête SQL est une instruction qui permet de récupérer ou de manipuler des données dans une base de données relationnelle.
Pourquoi utiliser le langage SQL ?
Le langage SQL est utilisé pour gérer et manipuler des données dans des bases de données relationnelles, ce qui est essentiel pour de nombreux domaines tels que la science des données, l’informatique et la finance.
Qu’est-ce qu’un aide-mémoire des commandes SQL ?
Un aide-mémoire des commandes SQL est un document qui résume les commandes les plus courantes du langage SQL, ce qui permet de les utiliser rapidement et efficacement.
À lire aussi sur le site
Pour aller plus loin
Questions fréquentes.
Comment réussir aide-mémoire des commandes sql comment apprendre sql en 10 minutes ?
Je suis chercheur en intelligence artificielle, donc l une des principales choses dont je m occupe, ce sont les données. Beaucoup de données. Avec plus de 2,5 exaoctets de données générées chaque jour
Quel est le matériel nécessaire pour aide-mémoire des commandes sql comment apprendre sql en 10 minutes ?
Le matériel dépend du contexte précis. Reportez-vous à la section dédiée dans cet article pour la liste détaillée et nos recommandations.
Combien de temps faut-il prévoir pour aide-mémoire des commandes sql comment apprendre sql en 10 minutes ?
Selon votre niveau et le contexte, comptez généralement entre 30 minutes et plusieurs heures. Les détails de durée sont précisés dans le guide.
Quelles sont les erreurs à éviter ?
Les erreurs les plus fréquentes sont détaillées dans cet article, avec les bonnes pratiques pour les éviter et obtenir un résultat satisfaisant.
Commentaires
Chargement…